5 minutes
Regression Models
This page lists the most common regression algorithms with sample code for each. We run each model on the Wine Quality public dataset available on the UCI website.

Table of Contents
- Load Data
- Split Train/Test
- Model Evaluation
- Linear Regession
- Ridge Regession
- Lasso
- Elastic Net
- Quantile Regression
- KNN
- SVM
- Decision Tree
- Random Forest
- Adaboost
- XGBOOST
- LightGBM
- MLP
- LazyPredict
- Conclusion
Load Data
import pandas as pd
data = pd.read_csv("data/winequality-white.csv", sep=';')
data.head()
Split Train-Test
The data contains 4898 rows, 11 features and 1 target variable (quality). From then on, we'll use x_train as the training set and x_test as the testing set.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data.iloc[:,:-1],
data.iloc[:,-1],
test_size=0.3,
random_state=123)Model Evaluation
We evaluate each model based on a several common metrics:
- \(R^2\)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- Mean Absolute Error (MAE)
- Mean Absolute Percentage Error (MAPE)
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
def evaluate_model(y_pred, y_test, verbose=True):
# Performance
perf = {}
perf['r2'] = r2_score(y_test, y_pred)
perf['MSE'] = mean_squared_error(y_test, y_pred, squared=True)
perf['RMSE'] = mean_squared_error(y_test, y_pred, squared=False)
perf['MAE'] = mean_absolute_error(y_test, y_pred)
perf['MAPE'] = mean_absolute_percentage_error(y_test, y_pred)
if verbose:
for p in perf:
print("%s: %.3f" % (p, perf[p]))
return perfLinear Regression
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)Ridge Regression
from sklearn.linear_model import Ridge
model = Ridge(alpha=.1, # regularization parameter : ||y - Xw||^2_2 + alpha * ||w||^2_2
fit_intercept=True)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)Lasso
from sklearn.linear_model import Lasso
model = Lasso(alpha=.1, # regularization parameter : ||y - Xw||^2_2 + alpha * ||w||_1
fit_intercept=True)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)Elastic Net
from sklearn.linear_model import ElasticNet
# Objective function:
# 1 / (2 * n_samples) * ||y - Xw||^2_2 + alpha * l1_ratio * ||w||_1 + 0.5 * alpha * (1 - l1_ratio) * ||w||^2_2
model = ElasticNet(l1_ratio=0.5, # regularization parameter
alpha=.1, # regularization parameter
fit_intercept=True)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)Quantile Regression
from sklearn.linear_model import QuantileRegressor
model = QuantileRegressor(quantile=.5,
alpha=1.0, # regularization parameter for L1 penalty
fit_intercept=True)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)KNN
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
model = KNeighborsRegressor(n_neighbors=5, # number of neighbors
weights='uniform', # or ‘distance’
p=2, # Minkowski metric: p=1 is manhattan distance and p=2 is euclidean distance
metric='minkowski')
model.fit(x_train_scaled, y_train)
y_pred = model.predict(x_test_scaled)SVM
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
model = SVR(kernel='rbf',
C=1.0)
model.fit(x_train_scaled, y_train)
y_pred = model.predict(x_test_scaled)Decision Tree
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(max_depth=None, # if None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples
min_samples_split=2, # minimum number of samples required to split an internal node
min_samples_leaf=1, # minimum number of samples required to be at a leaf node
max_features=None, # if None, then max_features=n_features; can be 'sqrt' for sqrt(n_features)
random_state=123)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)Random Forest
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100,
max_depth=None, # if None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples
min_samples_split=2, # minimum number of samples required to split an internal node
min_samples_leaf=1, # minimum number of samples required to be at a leaf node
max_features='sqrt', # if None, then max_features=n_features; can be 'sqrt' for sqrt(n_features)
random_state=123)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)Adaboost
from sklearn.ensemble import AdaBoostRegressor
model = AdaBoostRegressor(n_estimators=100,
learning_rate=1.0,
loss='linear',
random_state=123)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)XGBOOST
import xgboost as xgb
dtrain = xgb.DMatrix(data=x_train, label=y_train)
dtest = xgb.DMatrix(data=x_test, label=y_test)
params = {'objective':'reg:squarederror',
'eval_metric': 'rmse',
'colsample_bytree': 0.6,
'min_child_weight':1.0,
'max_depth':6,
'eta':0.05, # learning_rate
'lambda':1.0, # L2 regularization parameter
'alpha':0.0, # L1 regularization parameter
'random_state':123}
model = xgb.train(params,
dtrain,
500,
evals=[(dtrain, 'train'), (dtest, 'test')],
maximize=False,
early_stopping_rounds=5,
verbose_eval=10)
y_pred = model.predict(dtest)LightGBM
import lightgbm as lgb
params = {
"objective" : "regression",
"metric" : "rmse",
"num_leaves" : 100,
"learning_rate" : 0.001,
"bagging_fraction" : 0.6,
"feature_fraction" : 0.6,
"bagging_frequency" : 6,
"bagging_seed" : 42,
"verbosity" : -1,
"seed": 42
}
lg_train = lgb.Dataset(data=x_train, label=y_train)
lg_test = lgb.Dataset(data=x_test, label=y_test)
model = lgb.train(params,
lg_train,
5000,
valid_sets=[lg_train, lg_test],
early_stopping_rounds=100,
verbose_eval=150,
evals_result=evals_result_lgbm)
y_pred = model.predict(x_test, num_iteration=model.best_iteration)MLP
from sklearn.neural_network import MLPRegressor
model = MLPRegressor(hidden_layer_sizes=(100,),
activation='relu',
solver='adam',
alpha=0.0001, # L2 penalty,
learning_rate='adaptive',
random_state=123)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)LazyPredict
LazyPredict is a Python package that builds a lot of basic models to get a quick overview of which models works better without any parameter tuning.
import lazypredict
from lazypredict.Supervised import LazyRegressor
reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(x_train, x_test, y_train, y_test)
print(models)| Model | Adjusted R-Squared | R-Squared | RMSE | Time Taken |
|---|---|---|---|---|
| SVR | 0.83 | 0.88 | 2.62 | 0.01 |
| BaggingRegressor | 0.83 | 0.88 | 2.63 | 0.03 |
| NuSVR | 0.82 | 0.86 | 2.76 | 0.03 |
| RandomForestRegressor | 0.81 | 0.86 | 2.78 | 0.21 |
| XGBRegressor | 0.81 | 0.86 | 2.79 | 0.06 |
| GradientBoostingRegressor | 0.81 | 0.86 | 2.84 | 0.11 |
| ExtraTreesRegressor | 0.79 | 0.84 | 2.98 | 0.12 |
| AdaBoostRegressor | 0.78 | 0.83 | 3.04 | 0.07 |
| HistGradientBoostingRegressor | 0.77 | 0.83 | 3.06 | 0.17 |
| PoissonRegressor | 0.77 | 0.83 | 3.11 | 0.01 |
| LGBMRegressor | 0.77 | 0.83 | 3.11 | 0.07 |
| KNeighborsRegressor | 0.77 | 0.83 | 3.12 | 0.01 |
| DecisionTreeRegressor | 0.65 | 0.74 | 3.79 | 0.01 |
| MLPRegressor | 0.65 | 0.74 | 3.80 | 1.63 |
| HuberRegressor | 0.64 | 0.74 | 3.84 | 0.01 |
| GammaRegressor | 0.64 | 0.73 | 3.88 | 0.01 |
| LinearSVR | 0.62 | 0.72 | 3.96 | 0.01 |
| RidgeCV | 0.62 | 0.72 | 3.97 | 0.01 |
| BayesianRidge | 0.62 | 0.72 | 3.97 | 0.01 |
| Ridge | 0.62 | 0.72 | 3.97 | 0.01 |
| TransformedTargetRegressor | 0.62 | 0.72 | 3.97 | 0.01 |
| LinearRegression | 0.62 | 0.72 | 3.97 | 0.01 |
| ElasticNetCV | 0.62 | 0.72 | 3.98 | 0.04 |
| LassoCV | 0.62 | 0.72 | 3.98 | 0.06 |
| LassoLarsIC | 0.62 | 0.72 | 3.98 | 0.01 |
| LassoLarsCV | 0.62 | 0.72 | 3.98 | 0.02 |
| Lars | 0.61 | 0.72 | 3.99 | 0.01 |
| LarsCV | 0.61 | 0.71 | 4.02 | 0.04 |
| SGDRegressor | 0.60 | 0.70 | 4.07 | 0.01 |
| TweedieRegressor | 0.59 | 0.70 | 4.12 | 0.01 |
| GeneralizedLinearRegressor | 0.59 | 0.70 | 4.12 | 0.01 |
| ElasticNet | 0.58 | 0.69 | 4.16 | 0.01 |
| Lasso | 0.54 | 0.66 | 4.35 | 0.02 |
| RANSACRegressor | 0.53 | 0.65 | 4.41 | 0.04 |
| OrthogonalMatchingPursuitCV | 0.45 | 0.59 | 4.78 | 0.02 |
| PassiveAggressiveRegressor | 0.37 | 0.54 | 5.09 | 0.01 |
| GaussianProcessRegressor | 0.23 | 0.43 | 5.65 | 0.03 |
| OrthogonalMatchingPursuit | 0.16 | 0.38 | 5.89 | 0.01 |
| ExtraTreeRegressor | 0.08 | 0.32 | 6.17 | 0.01 |
| DummyRegressor | -0.38 | -0.02 | 7.56 | 0.01 |
| LassoLars | -0.38 | -0.02 | 7.56 | 0.01 |
| KernelRidge | -11.50 | -8.25 | 22.74 | 0.01 |
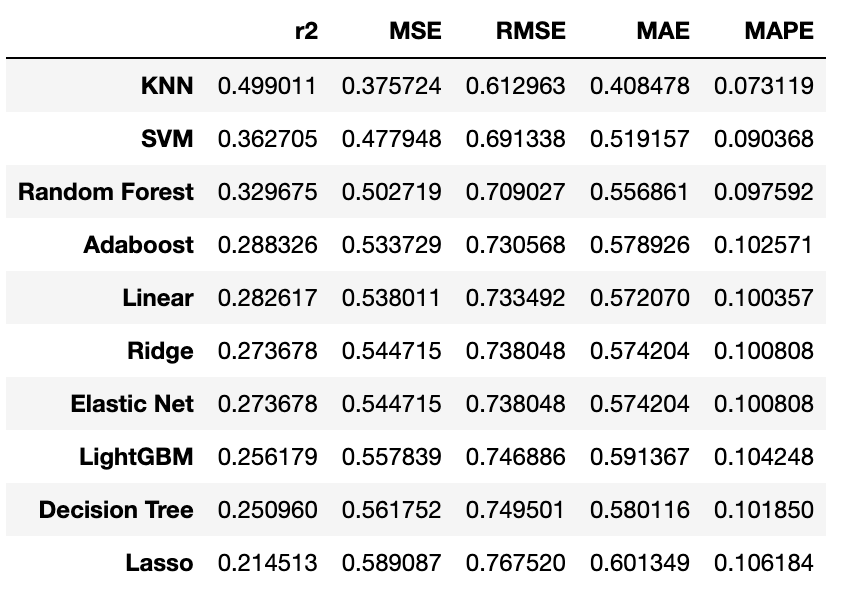
Conclusion