One minute
Web Scraping
Extracting content and data from a wesbite is called web scraping and it can be very useful to build yourself a dataset.
The most common Python library for Web scraping is called BeautifulSoup, but pandas also allows you to do some simple web scraping and can return tables from a web page as a list of dataframes.
In this example, we would like to gather the list of tickers from the components of the CAC40. Here is the Wikipedia table:
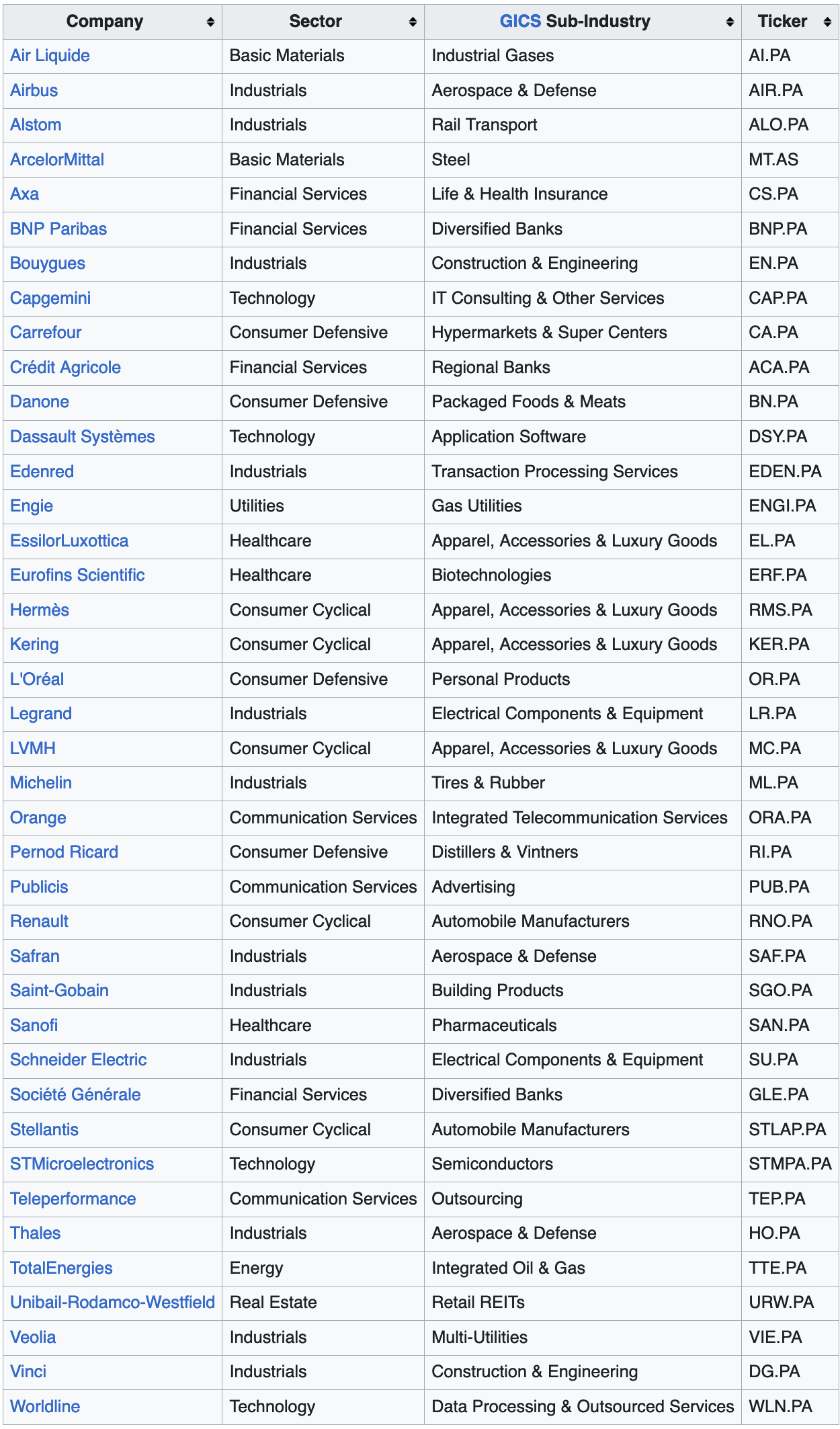
Using Pandas
import pandas as pd
# pd.read_html returns a list of dataframes
list_df = pd.read_html('https://en.wikipedia.org/wiki/CAC_40')
# in our case, it is the third table:
df = list_df[3]
# You can also pass the 'id' of the table (by inspecting the web page)
list_df = pd.read_html('https://en.wikipedia.org/wiki/CAC_40', attrs={'id': 'constituents'})
# and take the first element of the list
df = list_df[0]Using Beautiful Soup
BeautifulSoup is more versatile than pandas as you can see in the documentation
Using the same example as above:
import requests
from bs4 import BeautifulSoup
response = requests.get('https://en.wikipedia.org/wiki/CAC_40')
if response.ok:
soup = BeautifulSoup(response.text,'html.parser')
elem = soup.find('table', id='constituents')
# we use pd.read_html again, this time giving it an HTML string
df = pd.read_html(str(elem))[0]